
Riconoscimento oggetti mediante Droni
https://europepmc.org/article/pmc/6695703#B32-sensors-19-03371
Rilevamento multiplo in tempo reale a base di apprendimento profondo e monitoraggio delle immagini aeree tramite un robot volante con dispositivi incorporati basati su GPU.
Riassunto:
Negli ultimi anni, la domanda è aumentata per il rilevamento e il tracciamento dei oggetti da immagini aeree tramite droni utilizzando sensori e dispositivi a bordo del drone. Proponiamo un metodo molto efficace per questa applicazione basato su un framework di Deep Learning. Un sistema hardware integrato all’avanguardia consente a questi piccoli robot volanti di eseguire l’elaborazione a bordo in tempo reale necessario per il tracciamento degli oggetti. Sono stati sviluppati due tipi di moduli incorporati: uno è stato progettato utilizzando un Jetson TX o AGX Xavier e l’altro è stato basato su un Intel Neural Compute Stick. Questi sono adatti per la potenza di calcolo a bordo in tempo reale su piccoli droni volanti con ridotte dimensioni. È stata eseguita un’analisi comparativa degli attuali algoritmi di rilevamento multi-oggetto basati sul Deep Learning (l’apprendimento profondo), utilizzando i moduli di elaborazione incorporati basati su GPU designati per ottenere dati metrici dettagliati sui frame rate, nonché la potenza di calcolo. Introduciamo anche un efficace approccio al tracciamento dell’oggetto Targhet per gli oggetti in movimento. L’algoritmo per il monitoraggio degli oggetti in movimento si basa sull’estensione del semplice monitoraggio online e in tempo reale. È stato sviluppato integrando un approccio metrico di associazione basato sull’apprendimento profondo con un semplice monitoraggio online e in tempo reale (Deep SORT), che utilizza una metodologia di monitoraggio delle ipotesi con il filtro di Kalman e una metrica di associazione basata sull’apprendimento profondo. Inoltre, viene introdotto un sistema di guida che tiene traccia della posizione target utilizzando un algoritmo basato su GPU. Infine, dimostriamo l’efficacia degli algoritmi proposti mediante esperimenti in tempo reale con un piccolo drone multirotore.
1. Introduzione
Il rilevamento di oggetti Target (bersaglio) ha attirato un’attenzione importante per gli aeromobili autonomi grazie ai suoi notevoli vantaggi e ai recenti progressi. Il tracciamento del Target con un aeromobile senza pilota (UAV) può essere utilizzato per missioni di intelligence, sorveglianza e ricognizione [1]. Il monitoraggio del Target può essere utilizzato nei veicoli autonomi per lo sviluppo di sistemi di guida [2]. Il rilevamento dei pedoni [3], il rilevamento dinamico dei veicoli e il rilevamento degli ostacoli [4] possono migliorare le caratteristiche del sistema di assistenza alla guida. Le tecnologie di riconoscimento degli oggetti per i veicoli a guida autonoma hanno requisiti rigorosi in termini di precisione, univocità, robustezza, richiesta di spazio e costi [5]. Allo stesso modo, il riconoscimento degli oggetti e le funzioni di tracciamento in un aeromobile possono aiutare nella navigazione con i droni e nell’evitare gli ostacoli. I sistemi di riconoscimento visivo in un UAV possono essere utilizzati in molte applicazioni, come la videosorveglianza, i sistemi di guida autonoma [6], una vista aerea panoramica per la gestione del traffico, la sorveglianza del traffico, le condizioni stradali e la risposta alle emergenze, che è stato l’interesse del trasporto dipartimenti per molti anni [2,7].
In precedenza, il rilevamento del Target nei sistemi di droni utilizzava principalmente algoritmi di ricerca del Target basati sulla visione. Ad esempio, un Raspberry Pi e OpenCV sono stati utilizzati per trovare un obiettivo [8]. Tuttavia, le tecniche di visione artificiale potrebbero fornire risultati meno accurati e avere problemi nella previsione di dati futuri sconosciuti. D’altra parte, gli algoritmi di rilevamento dei Target di machine learning possono fornire un risultato molto accurato e il modello può fare previsioni da dati futuri non conosciuti. I sistemi di riconoscimento visivo che coinvolgono la classificazione, la localizzazione e la segmentazione delle immagini hanno ottenuto straordinari contributi di ricerca [6]. Inoltre, l’apprendimento approfondito ha compiuto grandi progressi nella risoluzione di problemi nei settori della visione artificiale, dell’elaborazione di immagini e video e della multimedialità [9]. A causa dei progressi critici nelle reti neurali, in particolare nell’apprendimento profondo [10], questi sistemi di riconoscimento visivo hanno mostrato un grande potenziale nel tracciamento dei Target.
I sistemi terrestri a bordo e fuori bordo sono piattaforme promettenti in questo contesto. Il più delle volte, il sistema dell’aeromobile non può essere dotato di dispositivi pesanti a causa del peso e del consumo energetico. Pertanto, i sistemi di terra fuori bordo svolgono un ruolo fondamentale. In alcuni casi, la comunicazione con la stazione di terra potrebbe essere impossibile a causa della distanza o della copertura. Un sistema di bordo in grado di supportare sia il peso che il consumo energetico sarebbe un quadro perfetto per una tale situazione e ambiente.
Un sistema di rilevamento di oggetti reali incorporato è stato sviluppato per un sistema di allarme che utilizza un UAV [11], ma hanno utilizzato solo un algoritmo specifico con diverse risoluzioni come input e uno specifico modulo incorporato. Nel presente studio, abbiamo utilizzato vari algoritmi e un diverso sistema integrato per eseguire gli algoritmi. Il progetto Deep Drone ha utilizzato una GPU Jetson e una R-CNN più veloce per rilevare e tracciare gli oggetti [12]. Nel nostro studio, abbiamo utilizzato Jetson AGX Xavier per prestazioni migliori.
Una GPU migliora le prestazioni in un sistema di riconoscimento visivo basato sull’apprendimento profondo. Tuttavia, un tale sistema ha anche alcuni svantaggi come un maggiore consumo di energia rispetto alle CPU e sono ovviamente più costosi di un sistema con CPU incorporata. Queste situazioni possono essere superate implementando un neural computing stick con un dispositivo CPU, che è un vincolo per l’esecuzione di modelli di deep learning. Tuttavia, il sistema sviluppato può essere costretto a funzionare in modo efficiente mediante l’ottimizzazione nell’unità di elaborazione. In questo documento, disquisiamo di un sistema di bordo e di fuori bordo che è stato sviluppato per un aeromobile utilizzando algoritmi di rilevamento di oggetti ben noti.
2. Sviluppo dell’hardware del Drone
Il sistema di rilevamento e tracciamento del Target può essere facilmente implementato in un aeromobile. La struttura dell’aeromobile è la stessa per tutti gli algoritmi ad eccezione di alcune piccole modifiche nel sistema integrato e nella struttura della carrozzeria esterna. La figura 1 presenta il progetto CAD 3D dell’aeromobile. La tabella 1 presenta le specifiche fisiche primarie del sistema del drone e della telecamera montata sul drone. La Figura 2 illustra le configurazioni hardware integrate utilizzate per il sistema di rilevamento e tracciamento del target. La Figura 3 mostra la configurazione hardware dettagliata dei sistemi integrati utilizzati per il rilevamento e il sistema di tracciamento del target.

figura 1

Figura 2
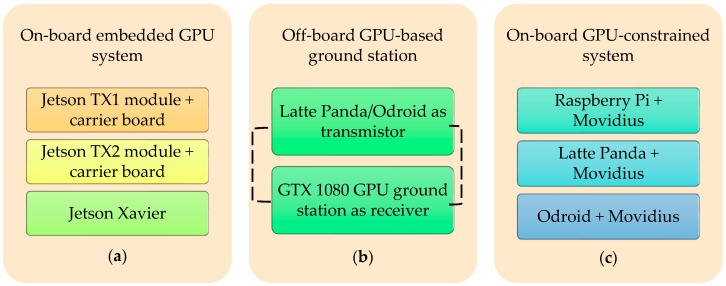
Figura 3
Tabella 1
Specifiche del Drone e della telecamera
| Sistema | Descrizione | Dimensioni |
|---|---|---|
| UAV | Tipo di configurazione | Conf-X |
| Dimensioni (incluse eliche) | 30 cm×30 cm×25 cm | |
| Tempo di volo | 20 min | |
| Payload (totale) | 2.5 kg | |
| Altitudine | 300 m | |
| Camera (oCam: 5-MP USB 3.0 Camera) |
Dimensioni | 42 mm×42 mm×17 mm |
| Peso | 35 g | |
| Risoluzione | 1920 × 1080@30 fps |
2.1. Specifiche tecniche dei diversi dispositivi integrati utilizzati per il rilevamento e il monitoraggio dei Target
Il nostro obiettivo principale era sui moduli Jetson [13] per il rilevamento dei Target. Oltre ai moduli Jetson, abbiamo utilizzato dispositivi con vincoli di GPU come Raspberry Pi [14], Latte Panda [15] e Odroid Xu4 [16]. Un Movidius NCS [17] è stato utilizzato per aumentare la potenza di elaborazione di questi dispositivi limitati. Inoltre, abbiamo provato un approccio diverso in cui abbiamo trasmesso i dati dell’immagine aerea alla stazione di terra che era equipaggiata con GTX 1080 [18]. L’uscita di rilevamento del bersaglio proveniva direttamente dalla stazione di terra. Di seguito, diamo una breve discussione sui dispositivi incorporati.
2.1.1. Moduli NVidia Jetson (TX1, TX2 e AGX Xavier)
I dispositivi NVidia Jetson sono piattaforme di calcolo AI integrate che forniscono supporto per il calcolo ad alte prestazioni e basso consumo per l’apprendimento profondo e la visione artificiale. I moduli Jetson possono essere aggiornati con NVidia JetPack SDK, che contiene TensorRT, OpenCV, CUDA Toolkit, cuDNN e L4T con il kernel Linux LTS [19].
Jetson TX1 è il primo supercomputer al mondo su un modulo e può fornire supporto per applicazioni di visual computing. È costruito con l’architettura NVidia Maxwell ™ e 256 core CUDA che offrono prestazioni di oltre un teraflop [20].
Jetson TX2 è uno dei dispositivi di elaborazione AI integrati più veloci ed efficienti dal punto di vista energetico. Questo supercomputer da 7,5 watt su un modulo porta il vero computing AI all’edge. Per costruirlo è stata utilizzata una GPU della famiglia NVidia Pascal ™, caricata con 8 GB di memoria e 59,7 GB / s di larghezza di banda di memoria. Comprendeva un assortimento di interfacce per apparecchiature standard che ne semplificano l’integrazione in un’ampia gamma di hardware [21].
Jetson AGX Xavier ha ampiamente superato le capacità limite dei precedenti moduli Jetson. In termini di prestazioni ed efficienza nell’apprendimento profondo e nella visione artificiale, ha superato le macchine più autonome e i robot avanzati del mondo [22]. Questa potente workstation GPU per elaborazione AI funziona sotto i 30 W. È stata costruita attorno a una GPU NVidia Volta ™ con Tensor Core, due motori NVDLA e una CPU ARM a 64 bit a otto core. NVidia Jetson AGX Xavier è la più recente espansione allo stadio Jetson [23]. Questo computer con GPU AI può fornire 32 TeraOPS (TOPS) senza precedenti del calcolo del picco in un modulo compatto da 100 mm × 87 mm [24]. Il modulo di efficienza energetica di Xavier può essere implementato in macchine intelligenti di livello successivo per funzionalità autonome end-to-end. La tabella 2 mostra il confronto di base tra tutti loro.
Tabella 2
Confronto tra i moduli Jetson utilizzati per il rilevamento e il tracciamento del Target.
| TX1 1 | TX2 2 | AGX XAVIER 3 | |
|---|---|---|---|
| GPU | NVidia Maxwell™ GPU with 256 NVidia® CUDA® Cores | NVidia Pascal™ architecture with 256 NVidia CUDA cores | 512-core Volta GPU with Tensor Cores |
| DL Accelerator | None | None | (2x) NVDLA Engine |
| CPU | Quad-core ARM® Cortex®-A57 MPCore Processor | Dual-core Denver 2 64-bit CPU and quad-core ARM A57 complex | 8-Core ARM v8.2 64-bit CPU, 8-MB L2 + 4 MB L3 |
| MEMORY | 4 GB LPDDR4 Memory | 8 GB 128-bit LPDDR4 | 16 GB 256-bit LPDDR4x | 137 GB/s |
| STORAGE | 16 GB eMMC 5.1 Flash Storage | 32 GB eMMC 5.1 | 32 GB eMMC 5.1 |
| VIDEO ENCODE | 4K @ 30 | 2 4K @ 30 (HEVC) | 8 4K @ 60 (HEVC) |
| VIDEO DECODE | 4K @ 30 | 2 4K @ 30, 12-bit support | 12 4K @ 30 12-bit support |
| JetPack Support | Jetpack 2.0~3.3 | Jetpack 3.0~3.3 | JetPack 4.1.1 |
1 NVidia Jetson TX2 offre il doppio dell’intelligenza all’edge. Disponibile online: devblogs.nvidia.com/jetson-tx2-delivers-twice-intelligence-edge.
2 JETSON TX2. Disponibile online: www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-tx2.
3 Jetson AGX Xavier Developer Kit. Disponibile online: https://developer.nvidia.com/embedded/buy/jetson-agx-xavier-devkit
2.1.3. Movidius Neural Computing Sticks
Le reti neurali profonde (DNN) possono essere implementate tramite Intel Movidius Neural Compute Stick (NCS) utilizzando Intel Movidius Neural Compute SDK (NCSDK) nei dispositivi vincolati come Raspberry Pi, Latte Panda e Odroid. L’API Intel Movidius Neural Compute (NCAPI) è inclusa nell’NCSDK per compilare, profilare e convalidare DNN utilizzando C / C ++ o Python [17]. L’NCSDK ha due utilizzi generali [32]:
Lo strumento in NCSDK può essere utilizzato per la creazione di profili, l’ottimizzazione e la compilazione di un modello DNN sul sistema host.
NCAPI può essere utilizzato per accedere all’hardware del dispositivo di neural computing per accelerare le inferenze DNN prototipando un’applicazione utente sul sistema host.
L’NCS è stato progettato per l’elaborazione delle immagini utilizzando modelli di Deep Learning. L’elaborazione delle immagini richiede molte risorse e spesso viene eseguita lentamente su dispositivi come Raspberry Pi, Latte Panda e Odroid. Movidius NCS accelera il modello basato su deep learning su dispositivi vincolati che hanno meno potenza di elaborazione per i modelli di deep learning. I dispositivi vincolati sono Raspberry Pi, Latte Panda, Odroid, ecc. La dimensione dell’NCS è di circa 7 cm × 3 cm × 1,5 cm e ha un connettore USB3 di tipo A. NCS ha un’unità di elaborazione visiva (VPU) ad alte prestazioni a bassa potenza simile alla modalità “follow me” dei droni DJI per funzionalità basate sulla visualizzazione [33]. Può risparmiare spazio, denaro, larghezza di banda, peso e potenza durante la costruzione dell’hardware del drone.
2.2. L’architettura del sistema integrato sviluppato
In questa sezione, discutiamo in modo elaborato i sistemi che abbiamo utilizzato con il framework principale del drone. Lo scopo del sistema veicolare che abbiamo sviluppato in questo studio era quello di trovare Target durante la navigazione e seguendo i percorsi, come mostrato nella Figura 4. La manovra iniziale è il decollo da terra, come mostrato nella 1a e 2a posizione del drone e cercare il target, come mostrato nella 3a posizione del drone in Figura 4. Inoltre, la nostra visione era quella di confrontare tutti i sistemi rispetto ad un diverso punto di vista.
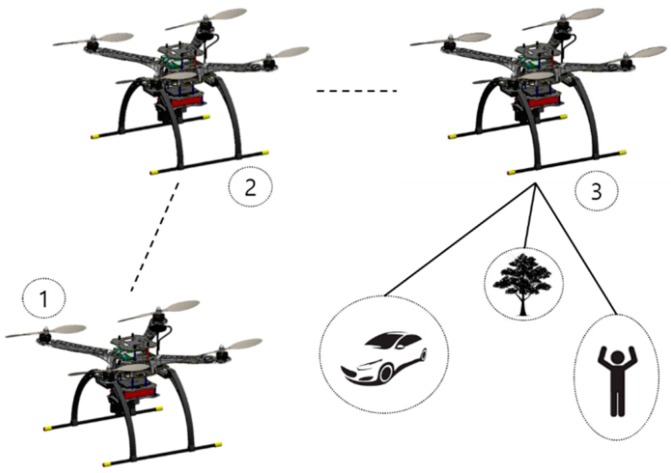
Figura 4
La rappresentazione dell’aeromobile alla ricerca di un bersaglio con un drone che decolla da terra, seguendo un waypoint designato e alla ricerca di oggetti.
2.2.1. Sistema GPU integrato
Il sistema GPU di bordo acquisisce le riprese aeree e invia i dati al TX1/TX2 di bordo, come mostrato nella Figura 5a, b. Il sistema genera un frame dei risultati del rilevamento con un nome e una percentuale di confidenza. In questo processo, TX1/TX2 è responsabile dell’elaborazione dell’intero algoritmo e dello streaming dei dati su una rete. La stazione di terra collegata a una rete simile riceve i dati di streaming e visualizza i risultati. Dall’output del monitoraggio è anche possibile ottenere il nome, l’affidabilità e la notifica del target rilevato. Successivamente, abbiamo implementato passaggi simili per Jetson AGX Xavier menzionato, come mostrato nella Figura 5c. Sembra che il potente sistema GPU Xavier possa funzionare bene ed in modo efficiente con algoritmi di rilevamento di oggetti come YOLO, SSD e R-CNN.
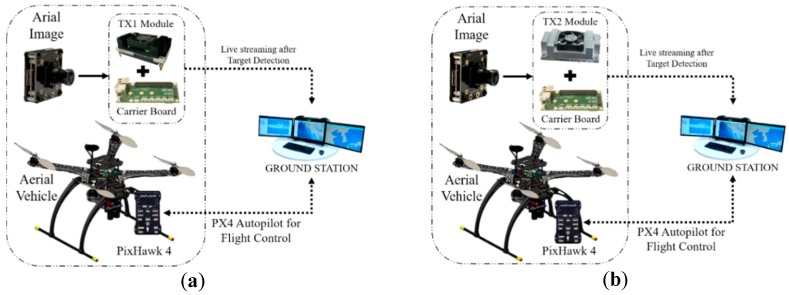
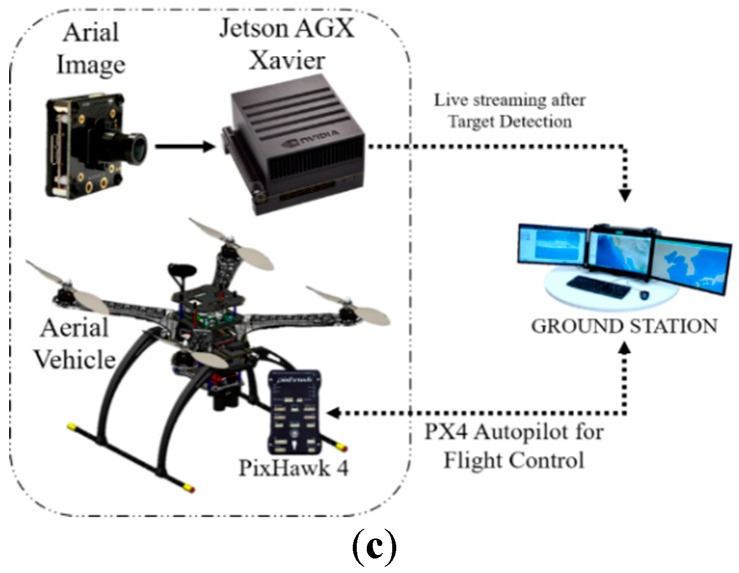
Figura 5
(a) Sistema di rilevamento del bersaglio a bordo che utilizza Jetson TX1, (b) Sistema di rilevamento del bersaglio a bordo che utilizza Jetson TX2 e (c) Sistema di rilevamento del Target a bordo che utilizza Jetson AGX Xavier.
2.2.2. Stazione di terra off-board basata su GPU
Un sistema a bordo drone di solito esegue tutto il lavoro da solo, ma in questo sistema il dispositivo di bordo esegue solo una parte del lavoro. Il dispositivo di bordo era responsabile dello streaming dei dati dell’immagine acquisita. Un processore di immagini in tempo reale e una configurazione del sistema di trasmissione sono stati stabiliti sull’UAV per comunicare con la stazione di terra. La stazione di terra basata su GPU ha ricevuto i dati e l’algoritmo ha utilizzato il sistema GPU GTX 1080 [18] per elaborare i dati dell’immagine grezza.
La Figura 6 mostra un diagramma dell’intera stazione di terra basata su GPU off-board. Successivamente, il bersaglio rilevato viene visualizzato con il nome e la confidenza sul monitor della stazione di lavoro a terra. Abbiamo utilizzato il socket Python [34] per trasmettere i dati sulla rete all’indirizzo IP specifico del drone. La GTX 1080 è un sistema molto potente per rilevare un oggetto o un bersaglio ed è veloce e fluido in questo sistema.
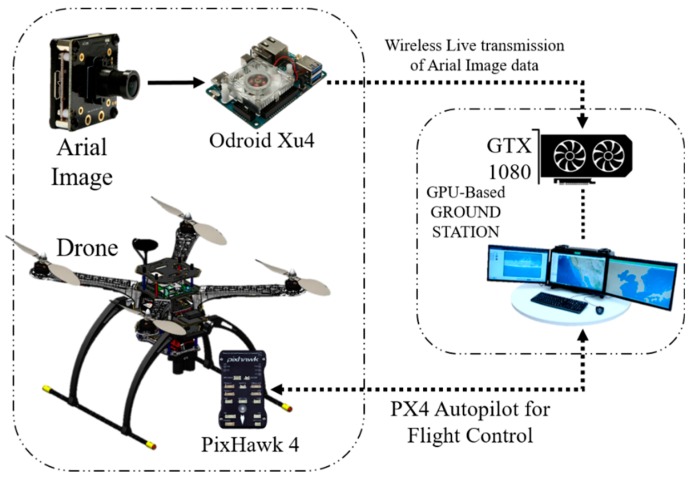
Figura 6
Rilevamento del Target utilizzando la stazione di terra basata su GPU da un aeromobile
2.2.3. Sistema vincolato dalla GPU integrato
Per costruire il sistema di bordo, abbiamo utilizzato dispositivi economici come il Raspberry Pi, che abbiamo combinato con uno stick neurale. Abbiamo provato SSD (Single Shot Multibox Detector) -Mobilenet [35,36] e l’algoritmo di rilevamento di oggetti YOLO [37] in questo framework. Allo stesso modo, abbiamo provato Latte Panda e Odroid XU4 in sostituzione del Raspberry Pi per verificare le prestazioni dei risultati di output, come mostrato nella Figura 7. Abbiamo anche eseguito un esperimento con SSD-Mobilenet senza l’uso del neural stick nel sistema.
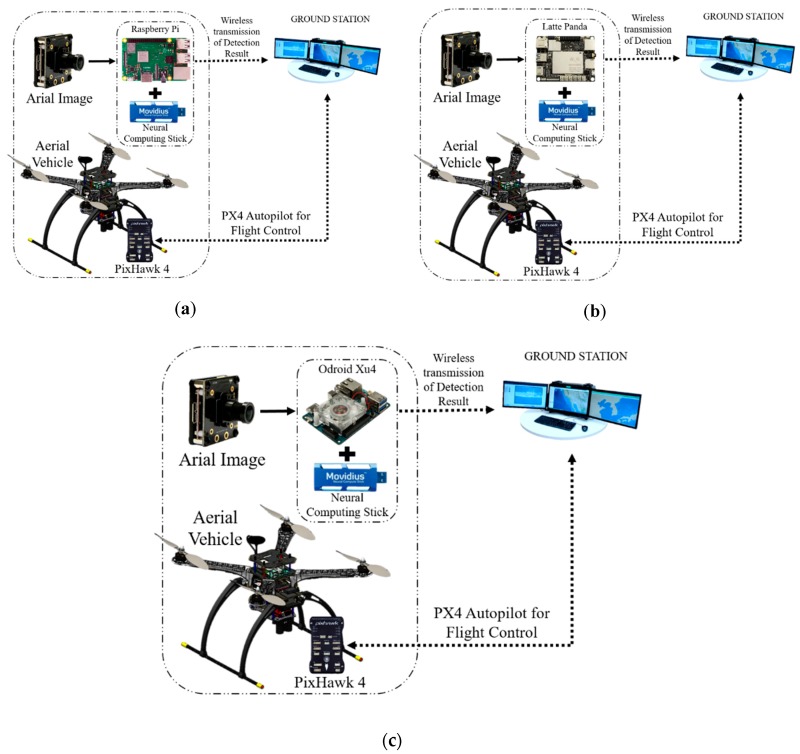
Figura 7
Sistema di rilevamento del Target a bordo con drone che utilizza dispositivi con vincoli di GPU come (a) Raspberry Pi, (b) Latte Panda e (c) Odroid Xu4.
2.3. Python Socket Server per inviare un’immagine alla stazione di terra basata su GPU
La programmazione socket [34] è utile per la comunicazione tra un server e un client che si trovano su due sistemi diversi. È un modo per connettere due nodi in cui un nodo utilizza un particolare indirizzo IP per raggiungere un altro nodo. Un server che trasmetterà l’immagine aerea deve specificare l’IP e la porta utilizzando una rete specifica a cui è connesso anche il client. Il server avvia e ascolta sempre la connessione in entrata. D’altra parte, il client sulla stessa rete raggiunge il server e ottiene il messaggio trasmesso, che nel nostro caso era l’immagine aerea.
Utilizzando una stazione di terra basata su GPU come client, abbiamo utilizzato un flusso di immagini continuo per i nostri scopi. Questo programma socket mostra un piccolo ritardo nel flusso di immagini in entrata a seconda del tipo di rete a cui sono connessi sia il server che il client. Tuttavia, non ha influenzato drasticamente le prestazioni del rilevamento del bersaglio. Questo strumento di comunicazione è stato utilizzato nel nostro sistema di stazione di terra basato su GPU off-board.
3. Algoritmo di rilevamento degli oggetti implementato nel sistema Drone
La Figura 8 mostra un diagramma dell’elenco degli algoritmi di apprendimento profondo utilizzato sui sistemi integrati per il sistema di tracciamento del target.
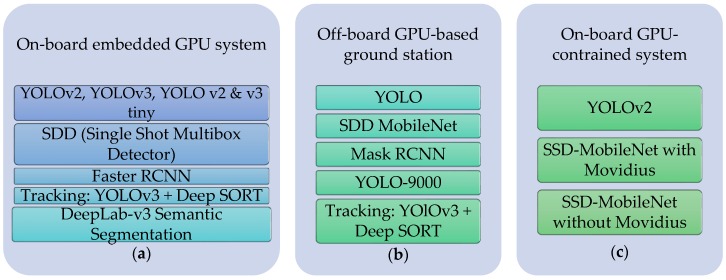
Figura Elenco degli algoritmi di deep learning implementati nell’aeromobile: (a) sistema GPU integrato a bordo; (b) stazione di terra off-board basata su GPU; (c) sistema a bordo GPU vincolato.
3.1. YOLO (You Only Look Once): rilevamento di oggetti in tempo reale
“Guarda solo una volta” (YOLO) [37] è un algoritmo di rilevamento rapido degli oggetti. Sebbene non sia più l’algoritmo di rilevamento degli oggetti più accurato, è un’ottima scelta quando è necessario il rilevamento in tempo reale senza perdita di accuratezza eccessiva. YOLO utilizza una singola rete CNN sia per la classificazione che per la localizzazione di un oggetto utilizzando i limiti [38]. L’architettura di YOLO è mostrata nella Figura 9.

Figura 9
Architettura di YOLO
3.1.1. YOLOv2
YOLO fornisce un’elaborazione in tempo reale con elevata precisione, ma presenta errori di localizzazione più elevati e una risposta di richiamo inferiore rispetto ad altri algoritmi di rilevamento basati sulla regione [39]. YOLOv2 [40] è una versione aggiornata di YOLO che supera la minore risposta di richiamo e aumenta la precisione con un rilevamento rapido. I cambiamenti in YOLOv2 sono discussi brevemente di seguito:
- Gli strati completamente connessi che sono responsabili della previsione del riquadro di confine sono stati rimossi.
- Uno strato di pooling è stato rimosso per rendere l’output spaziale della rete 13×13 invece di 7×7.
- La previsione della classe è stata spostata dal livello della cella al livello del riquadro di delimitazione. Ora, ogni previsione aveva quattro parametri per il riquadro di delimitazione [39].
- La dimensione dell’immagine in ingresso è stata modificata da 448×448 a 416×416. Ciò ha creato dimensioni spaziali con numeri dispari (cella della griglia 7×7 contro 8×8). Il centro di un’immagine è spesso occupato da un oggetto di grandi dimensioni. Con un numero dispari di celle della griglia, è più certo dove appartiene l’oggetto [39].
- L’ultimo strato di convoluzione è stato sostituito con tre strati convoluzionali 3×3, ciascuno dei quali emette 1024 canali di output per generare previsioni con dimensioni di 7×7×125. Quindi, è stato applicato uno strato convoluzionale 1×1 finale per convertire il 7×7×1024 uscita a 7×7× 25 [39].
3.1.2. YOLOv3
Le classi di oggetti di output si escludevano a vicenda poiché i classificatori presumevano che le etichette di output si escludessero a vicenda. YOLO aveva una funzione softmax per convertire i punteggi in probabilità che aggiungevano fino a uno. YOLOv3 [41] utilizza una classificazione multi-etichetta. Le etichette di output non esclusive possono mostrare un punteggio maggiore di uno. Invece di utilizzare la funzione softmax, YOLOv3 utilizza classificatori logistici indipendenti per calcolare la verosimiglianza dell’input appartenente a una specifica etichetta. YOLOv3 utilizza la perdita di entropia incrociata binaria per ciascuna etichetta invece dell’errore quadratico medio nel calcolo della perdita di classificazione. Evitando la funzione softmax si riduce la complessità del calcolo [39]. La Figura 10 [42] mostra l’architettura neurale di YOLOv3.
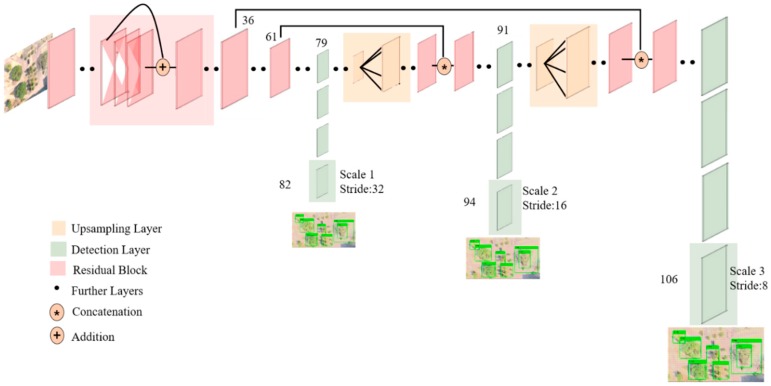
Figura 10
Architettura YOLOv3
3.1.3. YOLOv2 Tiny e YOLOv3 Tiny
Tiny YOLO si basa sulla rete di riferimento Darknet [43] ed è molto più veloce, ma meno preciso del normale modello YOLO [40,41]. Il modello YOLOv2 completo utilizza tre volte il numero di strati minuscolo e ha una forma leggermente più complessa. La versione “minuscola” di YOLO ha solo nove strati convoluzionali e sei strati di raggruppamento. Poiché YOLO tiny utilizza meno strati, è più veloce di YOLO, ma anche un po ‘meno preciso.
3.1.4. YOLO-9000
YOLO-9000 [40] è una versione migliore, più veloce e più forte di YOLO. Di seguito vengono mostrati brevi punti riguardanti la questione di renderlo migliore, più veloce e più forte [44].
Gli approcci per migliorare sono:
- Normalizzazione in batch: la normalizzazione in batch è stata utilizzata in tutti i livelli convoluzionali, il che ha contribuito a ottenere un miglioramento di oltre il 2% in mAP (precisione media media).
- Classificatore ad alta risoluzione: la rete di classificazione è stata ottimizzata su immagini 448 × 448 anziché addestrata con immagini 224 × 224. Ciò ha aiutato la rete a funzionare meglio a una risoluzione più alta. Questa rete di classificazione ad alta risoluzione ha dato un aumento del mAP di quasi il 4%.
- Convoluzionale con scatole di ancoraggio: in YOLOv2, le scatole di ancoraggio vengono adottate rimuovendo tutti gli strati completamente collegati. Uno strato di pooling è stato rimosso per aumentare la risoluzione dell’output dell’immagine. Ciò ha consentito la generazione di più box, il che ha migliorato il richiamo dall’81% (69,5 mAP) all’88% (69,2 mAP) [40].
- Previsione della posizione diretta: la previsione diventa più semplice se la posizione è vincolata o limitata. YOLO9000 prevede le coordinate di posizione relative alla posizione della cella della griglia, che limita la verità del terreno a cadere tra zero e uno. Non effettua previsioni utilizzando l’offset al centro del riquadro di delimitazione [44].
- Funzionalità a grana fine: è stato incluso uno strato pass-through come ResNet per utilizzare funzionalità a grana fine per la localizzazione di oggetti più piccoli.
- Addestramento su più scale: la stessa rete può prevedere a risoluzioni diverse se viene utilizzato un set di dati con risoluzioni diverse durante l’addestramento della rete. Ciò significa che la rete può effettuare previsioni da una varietà di dimensioni di input.
Gli approcci per il più veloce sono:
- Invece di utilizzare VGG-16, è stata utilizzata una rete personalizzata di 19 livelli convoluzionali e cinque livelli di pool massimo. La rete personalizzata utilizzata dal framework YOLO si chiama Darnet-19 [45].
Gli approcci per il più sostenuto sono:
- Classificazione gerarchica: per creare una previsione gerarchica, sono stati inseriti diversi nodi. Una categoria semantica è stata definita per ogni nodo a un livello. Pertanto, diversi oggetti in un’immagine possono essere amalgamati in un’unica etichetta poiché provenivano da un’etichetta semantica di livello superiore.
- Classificazione e rilevamento congiunti: per l’addestramento di un rilevatore su larga scala, sono stati utilizzati due tipi di set di dati. un set di dati di classificazione tradizionale che conteneva un gran numero di categorie e un set di dati di rilevamento [45].
3.2. SSD: rilevatore MultiBox a scatto singolo
Una tipica rete CNN riduce gradualmente le dimensioni della mappa caratteristica ed espande la profondità verso gli strati più profondi, come mostrato nella Figura 11. Campi ricettivi più grandi sono coperti dagli strati profondi, il che crea una rappresentazione più astratta. Campi recettivi più piccoli sono coperti dagli strati superficiali. Pertanto, la rete può utilizzare queste informazioni per prevedere oggetti grandi utilizzando strati più profondi e per prevedere oggetti piccoli utilizzando strati superficiali [36,46]. L’idea principale è quella di utilizzare un’unica rete per velocizzare e rimuovere la proposta di regione. Regola il riquadro di delimitazione in base alla previsione. Gli ultimi pochi strati sono responsabili della previsione del riquadro di delimitazione più piccolo, che è anche responsabile della previsione di riquadri di delimitazione diversi. La previsione finale è una combinazione di tutte queste previsioni. Per comprendere meglio SSD, la sua struttura è spiegata dal suo nome [47]:
- Single shot: le attività di localizzazione e classificazione degli oggetti vengono eseguite in un unico passaggio in avanti della rete.
- MultiBox: MultiBox è il nome di una tecnica per la regressione del riquadro di delimitazione sviluppata da Christian Szegedy et al. per proposte rapide di coordinate del riquadro di delimitazione indipendenti dalla classe [48,49].
- Rilevatore: la classificazione di un oggetto rilevato viene eseguita dalla rete, denominata rilevatore di oggetti.
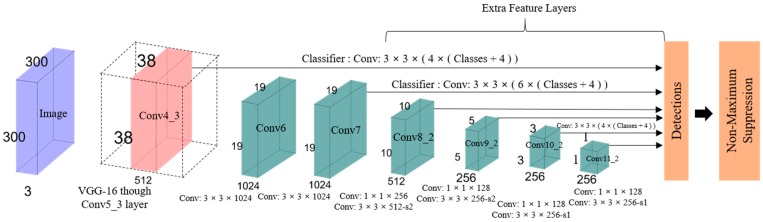
Figura 11
Architettura SSD
3.3. Metodo di rete convoluzionale basato su regione per il rilevamento di oggetti
L’obiettivo di R-CNN [50] è identificare correttamente gli oggetti principali attraverso il riquadro di delimitazione nell’immagine. R-CNN crea box di delimitazione delle regioni proposte utilizzando una tecnica chiamata ricerca selettiva [51]. Ad un livello elevato, la ricerca selettiva, mostrata nella Figura 12, esamina l’immagine attraverso riquadri di diverse dimensioni e ogni gruppo di dimensioni insieme per identificare gli oggetti. Una volta completato il processo, R-CNN deforma la regione in una dimensione quadrata standard e la passa alla versione modificata di AlexNet per trovare la regione valida. Nello strato finale della CNN, R-CNN aggiunge una macchina vettoriale di supporto (SVM), che classifica semplicemente determinando la possibilità di trovare un oggetto e il nome dell’oggetto [52].
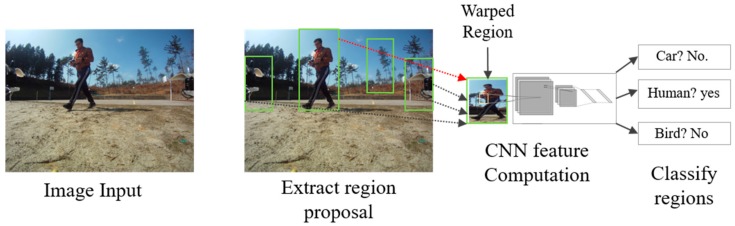
Figura 12
Dopo aver creato una serie di proposte di regione, R-CNN utilizza una versione modificata di AlexNet per determinare la regione valid
3.3.1. R-CNN più veloce
R-CNN funziona davvero bene, ma è piuttosto lento. Uno dei motivi è che richiede un passaggio in avanti della CNN (AlexNet) per ogni singola regione proposta per ogni singola immagine. Un altro motivo è che deve addestrare tre diversi modelli separatamente: la CNN per generare caratteristiche dell’immagine, il classificatore per prevedere la classe e il modello di regressione per restringere i limiti [52]. Più veloce R-CNN aggiunge una rete completamente convoluzionale oltre alle caratteristiche della CNN nota come rete di proposte regionali per accelerare la proposta regionale [53].
3.3.2. Maschera R-CNN
Mask R-CNN è una versione estesa della più veloce R-CNN per la segmentazione a livello di pixel. La maschera R-CNN [54] funziona inserendo un ramo in una R-CNN più veloce che aggiunge una maschera binaria per determinare se un dato pixel fa parte di un oggetto. La filiale è una rete completamente convoluzionale in cima a una mappa delle caratteristiche basata sulla CNN [52]. Una volta generate queste maschere, la maschera R-CNN le amalgama con le classificazioni e le caselle di delimitazione risultanti da una R-CNN più veloce. Nel complesso, genera una segmentazione precisa.
3.4. Segmentazione semantica DeepLab-v3
Abbiamo implementato il modello Deeblap di Tensorflow per la segmentazione semantica in tempo reale nelle piattaforme integrate [55,56]. È costruito su una potente architettura backbone CNN (convolutional neural network) [57,58] per ottenere i risultati più accurati, destinati alla distribuzione lato server. DeepLab-v3 è stato esteso includendo un semplice modulo decodificatore per perfezionare i risultati della segmentazione, specialmente lungo i confini degli oggetti, che sono molto efficaci. La convoluzione separabile in profondità è stata successivamente utilizzata in entrambi i moduli del decodificatore e nel pooling piramidale spaziale [59]. Di conseguenza, l’output era una rete codificatore-decodificatore più veloce e più forte per la segmentazione semantica.
4. Algoritmo di monitoraggio del bersaglio implementato nel sistema di droni
Sono disponibili molti algoritmi di tracciamento del target sia per più oggetti che per un singolo oggetto. La maggior parte di loro utilizza metodi convenzionali e reti neurali per il monitoraggio. Abbiamo implementato Deep SORT [60], che sembra fattibile per tracciare oggetti in tempo reale utilizzando il nostro sistema hardware.
4.1. Ordinamento profondo utilizzando YOLOv3
Lo scopo di questo progetto è di aggiungere il tracciamento degli oggetti a YOLOv3 [41] e ottenere il tracciamento degli oggetti in tempo reale utilizzando un semplice algoritmo di tracciamento online e in tempo reale (SORT) con una metrica di associazione profonda (Deep SORT) [60]. L’algoritmo integra le informazioni sull’aspetto per migliorare l’efficienza di SORT [61]. Pertanto, è possibile tracciare gli oggetti per un tempo più lungo attraverso le occlusioni visive. Inoltre, ha ridotto efficacemente il numero di cambi di identità del 45%. Un set di dati di reidentificazione delle persone su larga scala è stato utilizzato nella pre-formazione. Secondo il loro articolo, la sperimentazione ha anche mostrato prestazioni complessive a frame rate elevati.
SORT ha un difetto nel tracciamento attraverso le occlusioni poiché un oggetto in genere deve rimanere nella vista frontale della telecamera. Questo problema viene risolto con successo utilizzando una metrica più informata che combina le informazioni di movimento e aspetto invece della metrica di associazione. In particolare, una rete neurale convoluzionale (CNN) è stata implementata dopo essere stata addestrata utilizzando un set di dati di reidentificazione delle persone su larga scala per distinguere i pedoni.
L’algoritmo ungherese è stato utilizzato per risolvere l’associazione tra gli stati di Kalman previsti e le misurazioni appena arrivate. La formulazione matematica è stata risolta integrando le informazioni di movimento e aspetto attraverso la combinazione di due metriche appropriate. Entrambe le metriche sono state combinate utilizzando una somma ponderata per costruire il problema di associazione, ed è stata presentata la seguente equazione [60].
[1]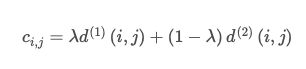
[2]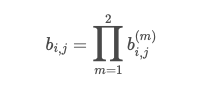
L’algoritmo 1 è stato preso direttamente da Deep SORT [60] e mostra l’algoritmo a cascata corrispondente che assegna la priorità agli oggetti visti più di frequente. Gli input erano l’indice della traccia T, indice di rilevamento D e age massima Amax. Il costo di associazione e la matrice del gate sono calcolati sulla riga 1 e riga 2. Il problema di assegnazione lineare dell’aumento dell’agenzia è stato risolto iterando la traccia age n. Il sottoinsieme di tracce Tn che non sono stati associati negli ultimi n frame di rilevamento è selezionato nella riga 6. L’assegnazione lineare tra le tracce in Tn e rilevamenti impareggiabili U viene risolto nella riga 7. L’insieme delle corrispondenze e dei rilevamenti non corrispondenti viene aggiornato nelle righe 8 e 9. Successivamente, il valore impostato viene restituito nella riga 11. Come l’algoritmo SORT originale [61], l’intersezione sull’associazione unione viene eseguita fase di corrispondenza. L’esecuzione della serie di tracce non confermate e non abbinate di età n = 1 aiuta a tenere conto di improvvisi cambiamenti di aspetto.
L’algoritmo 1. Cascata corrispondente.
Input: Indici traccia T= {1,…,N} , Indice di rilevamento D= {1,…,M}, Age massima Amax
- Compute cost matrix C=[ci,j] using Equation [1]
- Compute gate matrix B=[bi,j] using Equation [2]
- Initialize the set of matches M←∅
- Initialize the set of unmatched detections U←D
- For n∈{1, …, Amax} n∈{1, …, Amax} do
- Select tracks by age Tn←{i∈T | ai=n}
- [xi,j] ← min cost matching C, Tn, U
- M←M ∪ {(i,j) | bi,j. xi,j>0}
- U←U ∖ {j | Σi bi,j. xi,j>0}
- end for
- return M,U
È necessaria un’enorme quantità di dati per le persone fattibili che si attaccano sulla base di un apprendimento metrico profondo. Un’architettura CNN è stata addestrata su un dataset di reidentificazione della persona su larga scala [62], che contiene oltre 1.100.000 immagini di 1261 pedoni. La Tabella 4 presenta l’architettura CNN della sua rete [60]. Una rete residua ampia [63] con due strati contorzionali seguiti da sei blocchi residui è stato utilizzato nella loro architettura. Il batch finale e la normalizzazione l2 hanno proiettato la funzione sull’ipersphere dell’unità.
Tabella 4
Panoramica dell’architettura CNN
| Nome | Passo | Dimensione Output |
|---|---|---|
| Conv 1 | 32×128×64 | |
| Conv 2 | 32×128×64 | |
| Pool Max 3 | 32×64×32 | |
| Residuo 4 | 32×64×32 | |
| Residuo 5 | 32×64×32 | |
| Residuo 6 | 64×32×16 | |
| Residuo 7 | 64×32×16 | |
| Residuo 8 | 128×16×8 | |
| Residuo 9 | 128×16×8 | |
| Dense 10 | 128 | |
| Batch finale e la normalizzazione l2 | 128 |
4.2. Guidare l’UAV verso il Target usando Yolov2
Lo scopo di questo algoritmo era quello di volare il drone verso il Target usando solo un algoritmo di rilevamento. In questo caso, abbiamo usato una persona come classificatore e abbiamo calcolato l’area del riquadro di delimitazione della persona da una certa distanza di sicurezza, che sarà l’obiettivo finale per il drone. L’algoritmo 2 presenta l’algoritmo di orientamento verso il Target. Abbiamo usato Yolov2, ma può essere applicabile anche ai nostri algoritmi. Usando l’algoritmo Yolov2, possiamo facilmente ottenere coordinate per il riquadro di delimitazione e calcola il suo centro.
Inizialmente, l’algoritmo cerca il Target n = 1 nel passaggio 1 o non fa nulla e attende il Target come al punto 11. Se c’è un Target ed è una persona L = 1, l’algoritmo loop dal punto 4 a Passaggio 8. Nel passaggio 4, l’area del riquadro di delimitazione A è calcolato come un peso X altezza. Nel passaggio 5 e il punto 6, calcola
Errorcenter e Errorarea, i cui valori saranno utilizzati per l’angolo di imbardata e la velocità in avanti, rispettivamente. L’algoritmo eseguirà il passaggio 7 fino a quando Errorcenter = 0 e STEP 8 fino a Amax ≤ A.

5. Risultati
In questa sezione, presentiamo i risultati sperimentali dal veicolo aereo e dalle prestazioni in base ai sistemi che abbiamo utilizzato nel veicolo aereo.
5.1. Risultati del rilevamento con la classificazione dal drone utilizzando il sistema GPU di bordo
La figura 13 seguente mostra il risultato del rilevamento target con box di delimitazione e livelli di confidenze dal sistema GPU di bordo. La figura 13a mostra il risultato segmentato dall’UAV utilizzando Xavier come sistema GPU di bordo. Quando la persona era piccola o fuori dal campo visivo, questo algoritmo non è stato in grado di rilevare bene quella persona. D’altra parte, utilizzando R-CNN più veloce per il rilevamento ha mostrato un risultato molto accurato, ma ha rivelato un tasso di prestazione molto basso, come mostrato nella figura 13b, d. L’algoritmo YOLOV2 ha rivelato un risultato soddisfacente in termini di tasso di prestazione, ma potrebbe solo rilevare la persona a meno di 20 metri, come mostrato nella Figura 13C, G. Tuttavia, è possibile aumentare la dimensione dell’immagine in ingresso per rilevare una persona da una distanza. In tal caso, il tasso di prestazione sarà ridotto in termini di fotogrammi al secondo (FPS). Le nostre dimensioni di ingresso erano 416 × 416 per tutti gli algoritmi di rilevamento Yolo. Più significativamente, Yolov3 ha mostrato risultati più accurati anche da lontano a causa dei suoi potenti 75 strati convoluzionali, come mostrato nella figura 13e, f, i.


Figura 13
Risultati del rilevamento del Target di (A) Segmentazione in tempo reale utilizzando Deeplabv-3 utilizzando Xavier, (B) R-CNN più veloce con TX2, (c) Yolov2 utilizzando TX2, (D) più veloce R-CNN utilizzando Xavier, (E) Yolov3 utilizzando TX2, (f) Yolov3 utilizzando Xavier, (G) Yolov2 utilizzando Xavier, (h) SSD-caffe con Xavier, (i) Yolov3 utilizzando Xavier, e (J) SSD-caffe con TX2.
5.2. Risultati del rilevamento con la classificazione dal drone utilizzando il sistema a terra basato sulla GPU
La figura 14 mostra i risultati del rilevamento del Target del sistema di messa a terra basato sulla GPU. La figura 14a mostra il risultato segmentato dal sistema GPU off-board. L’ingresso dell’immagine aerea è venuto dal dispositivo Odroid XU4, che è stato collegato al drone. Figura 14b, H Mostra l’output di Yolov3 in questo sistema. Inoltre, abbiamo implementato la maschera R-CNN utilizzando questo sistema, come mostrato nella Figura 14D. Questo sistema aveva un divario di latenza a seconda del sistema di comunicazione, ma non ha influenzato il tasso di prestazione dell’algoritmo. Una vasta gamma di moduli di rete WiFi è stata utilizzata per rimanere connessi alla rete sia per il client che per il server.

Figura 14
Risultati del rilevamento del Target utilizzando la stazione terrestre basata sulla GPU off-board: (a) Segmentazione in tempo reale utilizzando Deeplabv-3, (B) Yolov3, (c) Mask-R-CNN, (D) SSD-MOBILENET, (E, f) Yolov2, (G) Yolo-9000m e (h) yolov3.
5.3. Risultati delle prestazioni tra il sistema di bordo e off-board
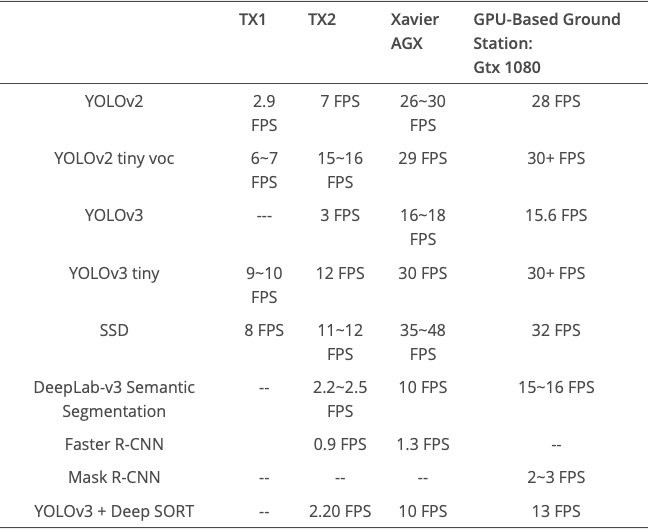
I risultati delle prestazioni sotto forma di fps sono mostrati nella tabella 5. Questa tabella fornisce un confronto quantitativo tra il sistema GPU incorporato di bordo e la stazione terrestre basata sulla GPU off-board. Questo confronto quantitativo cambierà con la dimensione di ingresso dell’immagine. Tuttavia, utilizzando questa tabella, si può scegliere il miglior algoritmo e sistema per un’operazione specifica.
Tabella 5.
Confronto delle prestazioni tra i moduli Jetson e GTX 1080 utilizzati per il rilevamento del target e il monitoraggio.
5.4. Risultato del monitoraggio del tipo profondo utilizzando Xavier e il sistema a terra basato su GPU off-board
La figura 15 mostra il risultato dell’uscita dell’algoritmo di tracciamento del bersaglio utilizzando Yolov3 sia nel sistema Xavier che nel sistema a terra basato sulla GPU.

Figura 15
I risultati del tracciamento del Target utilizzando il tipo profondo e Yolov3 dal drone utilizzando (A) Xavier e (B) la stazione terrestre basata sulla GPU off-board.
5.5. Il risultato del rilevamento dell’oggetto del sistema vincolato della GPU di bordo
La figura 16 mostra il risultato di uscita del rilevamento dell’oggetto da Movidius NSC con ODROID XU4. Questo sistema è un pacchetto adatto per UAV a basso carico e un sistema meno costoso. Sebbene il tasso di prestazione non fosse così soddisfacente come quello di un sistema incorporato di bordo, una piccola attività potrebbe essere eseguita utilizzando questo sistema. È un’opzione valida se è considerata un costo, lo spazio o la limitazione termica. Movidious ha il suo dissipatore di calore realizzato con la pinna metallica per aiutare con il raffreddamento.

Figura 16
Risultati del rilevamento del Target dal drone di (A) Yolo Tiny utilizzando Odroid XU4 + NCS e (B) SSD-MOBILENET utilizzando ODROID XU4 + NCS.
5.6. Risultati delle prestazioni del sistema vincolato della GPU di bordo
Le prestazioni quantitative derivano nella forma di fps sono mostrate nella Tabella 6 per i sistemi vincolati della GPU di bordo come Movidius NCS con Raspberry PI, Latte Panda e Odroid XU4. Questo sistema ha il potenziale per accelerare l’interfaccia in cui un dispositivo a bassa potenza non può eseguirlo da solo.
Tabella 6.
Confronto delle prestazioni tra Raspberry PI 3, Latte Panda e Odroid XU4.
| Sistema | YOLO | SSD Mobile Net |
|---|---|---|
| Movidius NCS + Raspberry Pi | 1 FPS | 5 FPS |
| Movidius NCS + Latte Panda | 1.8 FPS | 5.5~ 5.7 FPS |
| Movidius NCS + Odroid | 2.10 FPS | 7~8 FPS |
| Unicamente Odroid senza Movidius NCS | — | 1.4 FPS |
5.7. Risultato monitorato del consumo di energia
La figura 17 presenta l’utilizzo percentuale della GPU medio durante l’esecuzione di algoritmi diversi nel sistema incorporato come AGX Xavier e TX2. Tutti gli algoritmi hanno utilizzato il loro modello pre-addestrato fornito con esso.
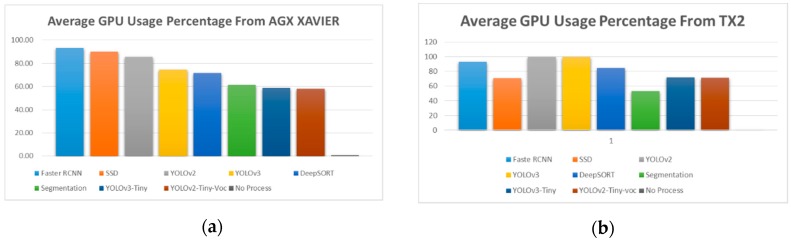
Figura 17
Percentuale media dell’utilizzo della GPU da (a) Xavier e (B) TX2.
La figura 18 presenta l’utilizzo della memoria in MB e l’utilizzo percentuale medio della CPU durante l’esecuzione di algoritmi diversi nei sistemi embedded come AGX Xavier. Sembra che la percentuale della CPU fosse quasi simile per tutto l’algoritmo (vicino al 4200). Nel caso di TX2, l’utilizzo della CPU era vicino a 3500 per tutti gli algoritmi.
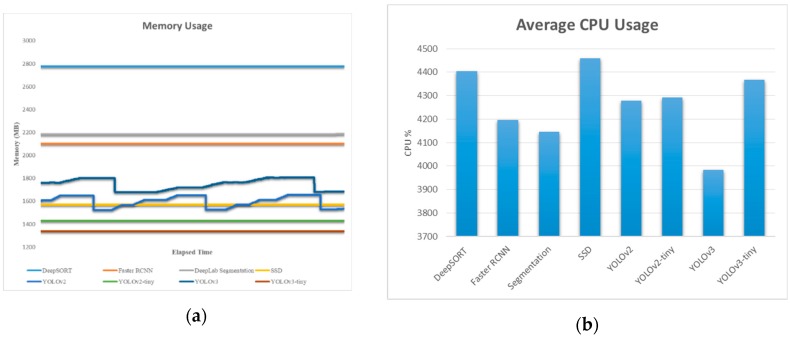
Figura 18
(a) Utilizzo della memoria e (b) Percentuale media dell’utilizzo della CPU in Xavier
5.8. Guidare l’UAV verso il Target
La figura 19 rappresenta la trama di errore tra il centro dell’immagine e il centro del Target utilizzando l’algoritmo YOLOV2. L’algoritmo ha ridotto l’errore tra il target e il centro dell’immagine utilizzando il movimento di imbardata del drone. Nel frattempo, ha anche tentato di ridurre l’errore tra l’area del riquadro di delimitazione del Target e l’area massima data utilizzando il movimento in avanti. Il movimento in avanti si è fermato quando ha raggiunto l’area massima data specificata per questo. Allo stesso modo, se l’errore è aumentato in una direzione negativa, l’UAV utilizzato il movimento all’indietro.
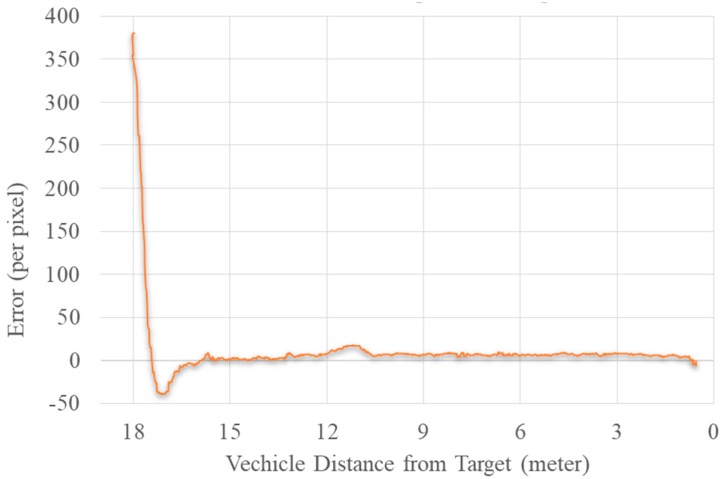
Figura 19
Schema del diagramma dell’errore tra l’immagine e il centro obiettivo contro la distanza
Il modulo incorporato TX2 è stato utilizzato per guidare l’UAV. L’errore tra due centri è stato utilizzato come feedback all’angolo di imbardata del veicolo. L’errore finale era equivalente a zero, e l’UAV era inferiore a 1 m dal bersaglio. Potremmo usare questo algoritmo per seguire il bersaglio. Precisione e alta frequenza fotogrammi sono stati i principali requisiti per questo algoritmo. A causa del rilevamento incoerente, l’UAV causerebbe un movimento tremante e un tasso di bassa prestazioni sabotare il processo dell’algoritmo.
6. Discussione
Poiché l’obiettivo principale di questo documento era sul rilevamento del target da un drone, dovevamo prima capire quale algoritmo forniva risultati più rapidi e più accurati anche da distanze lontane. Anche se Yolov2 era più veloce e preciso, non è stato possibile rilevare oggetti correttamente da lontano. Se la distanza tra il bersaglio e il drone era più di 20 m, il peso Yolov2 è diventato incapace di rilevare un essere umano. A causa dell’architettura di Yolov3, potrebbe rilevare un bersaglio anche a 50 metri dal drone. Pertanto, abbiamo cercato di implementare un tipo profondo con Yolov3 in un Jetson Xavier per il tracciamento di un bersaglio.
La versione Yolo Tiny non è adatta per il rilevamento target poiché è impreciso ed è difficile rilevare gli oggetti da lontano. L’algoritmo di tracciamento del bersaglio funzionava bene a 20-30 m di distanza, poiché all’interno di questo intervallo, la risoluzione della funzione dell’immagine è rimasta visibile per tracciare le funzionalità. È diventato più difficile da tenere traccia correttamente se l’oggetto di tracciamento ha perso la sua caratteristica a causa di distanze lontane. Sort profondo ha fornito un risultato di tracciamento contando un obiettivo di caratteristiche simili. Tuttavia, in alcuni casi, ha perso la traccia di una funzione contata e lo considerava come un nuovo obiettivo.
È chiaro che vi è stata un’influenza della risoluzione di input sulla rete neurale dell’algoritmo. Il frame del rilevamento è stato modificato rispetto alla dimensione di input che è stata alimentata all’architettura neurale dello Yolo [11]. Nel caso di Yolo, abbiamo usato 416×416.
Come nostra dimensione di ingresso nel file di configurazione dell’anno Yolo mentre esegue l’algoritmo di rilevamento target. Più significativamente, l’algoritmo guida per seguire il bersaglio per una persona ha funzionato a meno di 20 metri dall’obiettivo poiché il rilevamento della persona che usa Yolov2 non ha funzionato dopo tale limite. L’algoritmo guida è stato puramente basato sul risultato del rilevamento e dalle coordinate dei contenitori di delimitazione. Un risultato di rilevamento scadente o il monitoraggio scadente del box di delimitazione ha deviato il drone nella direzione sbagliata. Questo algoritmo ha anche avuto un’altra limitazione. Quando ha affrontato più bersagli di una classe simile, ha scelto in modo casuale tra loro da tracciare. È necessaria ulteriori ricerche per rendere l’algoritmo più robusto per tali scenari.
7. Conclusioni
Dai esperimenti su diversi sistemi GPU, è stato evidente che Jetson AGX Xavier è stato abbastanza potente da lavorare come sostituto di un sistema GPU come NVIDIA GTX 1080. Tutti i tipi di algoritmo di rilevamento del target contemporaneo si sono esibiti molto bene a Jetson Xavier. Jetson TX1 è fattibile se l’utente utilizza un piccolo peso o un modello come Yolov2 minuscolo. Poiché Yolov2 e V3 minuscolo hanno mostrato risultati FPS ragionevoli per il rilevamento dell’oggetto, non erano abbastanza buoni da rilevare un bersaglio da lontano. Inoltre, la potenza della fiducia per l’utilizzo del peso di Yolo Tiny era molto bassa.
Jetson TX2 è un sistema di GPU moderato. La performance non era come quella del Xavier, ma ha mostrato risultati eccezionali nel caso di Yolov2 e SSD-Caffe. Se c’era una limitazione nel peso del drone e il consumo energetico, un bastone informatico neurale attaccato al sistema è stato molto utile. Tra i tre sistemi vincolati in GPU di bordo, Odroid XU4 con NCS ha mostrato prestazioni migliori. Abbiamo anche presentato la procedura dell’algoritmo per il monitoraggio con il rispettivo sistema incorporato. Abbiamo anche presentato il runtime, il consumo della GPU e la dimensione della piattaforma utilizzata per l’esperimento.
Riferimenti
Vedere pagina dei riferimenti: http://sky53.com/riconoscimento-oggetti-mediante-droni-riferimenti/